Some good chats this week on reactive matters. Firstly on Tuesday with Patrick Dubroy, a fellow substratist. Patrick is a splendid chap who amongst many other works is the maintainer of a powerful, user-friendly parsing toolkit Ohm.
Patrick pinged me last week explaining that he was contemplating a collaboration with Camille and Yann who were building a document publishing pipeline sourced from, amongst other formats, AsciiDoc (for related details see Camille’s recent PhD thesis). This is an exciting potential cross-link between the work of members of the nascent substrates community.
Patrick said that the team had already written an Ohm grammar for AsciiDoc and were interested in making the pipeline implementation more incremental, and avoid recomputing too many intermediate results in large pipelines publishing 300-pages books and the like. To prime intuition, Patrick sent along an interactive Ohm grammar for arithmetic expressions.

Alien signals and Adapton
In turn I pinged with a link to Jackson Chu’s very interesting work on alien-signals which is being used in language tooling contexts in upcoming versions of Vue.js.
As well as performing very well Jackson has demonstrated the great flexibility of the core/personality split implementation style in producing a polyfill for the upcoming TC39 signals standard proposal. This is pretty helpful stuff and in particular unpacks the great flexibility needed around the implementation of “effects” which whilst in many signals implementations are a baked-in primitive, in practice need some unbundling around the details of a framework’s rendering pipeline. However IMO much more flexibility is required – more on this later.
Patrick said that a core requirement for his work is the ability to write relatively arbitrary computations that depend on Ohm’s internal mechanisms and can apply incremental parsing – you have some computation that transitively depends on some part of the input – one part can be marked dirty and just that portion of the output is recomputed. He has been surveying the space a bit to see what approaches make sense – he saw that in JS frontend frameworks signals have become a big thing. He was familiar with Adapton/miniAdapton – what’s unclear is how different is it to these.
This turns out to have been a strong interest of mine in recent months. When I pinged Geoffrey Litt earlier in the year about reactivity he pointed me to miniAdapton and his own TS implementation of it. After pottering with the algorithm a bit I was likewise fretful about how different it was to “commodity signals” and what guarantees it really supported. For the past couple of years I have been building Infusion 6 around an (increasingly hacked) distribution of preact-signals because I was attracted to its unusually comprehensive suite of test cases.
Reactivity and glitches
I recapped to Patrick the archaeology of glitches I had done in 2024, now written up in their own page. He had also been intrigued whether Adapton implemented the same algorithm as commodity signals and had come to pretty much the same conclusion. He also bemoaned the fact that such work had long been going on in separate silos with essentially no cross-citation or cross-pollination. One isolated exception was the Rust incremental computation framework salsa which is influenced both by Adapton and the JS incremental view framework glimmer.
Dan Ingalls’ Fabrik
Patrick helpfully pointed me to Dan Ingalls’ super-interesting 1988 system, Fabrik, which long predates the Lively Kernel work and also had bidirectional dataflow dependencies built-in. I had started talking about the old chestnut of the temperature conversion sample that I’d started with in my tiny 2015 PPIG paper, and he remembered that Fabrik includes just such a sample:
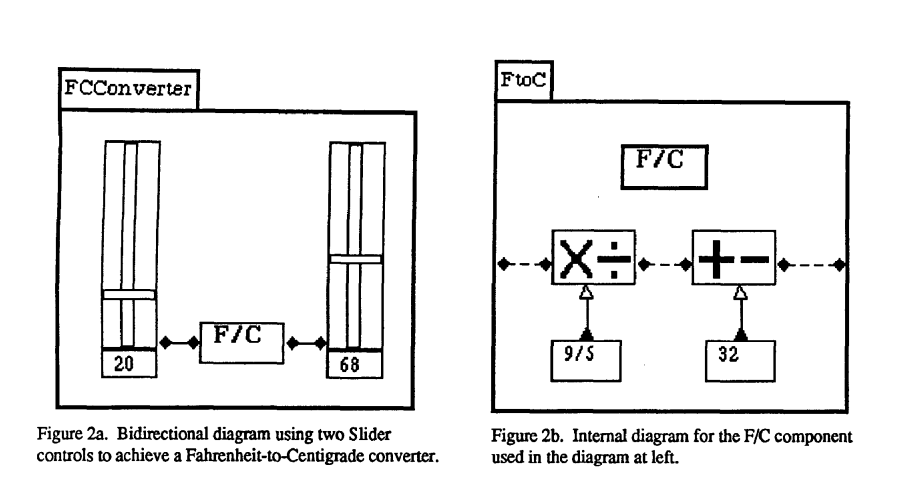
The Fabrik paper includes a really useful distinction:
The key observation about most uses of bidirectionality is that they are simply a shorthand for multiple paths of dataflow.
Bidirectionality in dataflow
This is just the kind of bidirectionality that I’ve meant to introduce into Infusion’s reactive system. I’ve talked rather airily of supporting “cyclic dataflow graphs” but Patrick reminded me that genuine cycles which are not degenerate require dedicated means of solving the dataflow state (iterative ones such as fixed-point or gradient descent of the kind seen in ThingLab or SketchPad) which I’ve not meant to put into scope. Fabrik’s distinction is just the one required and the paper helpfully writes out a “compilation” of the possibilities of the resulting alternating dataflow. So such a system is clearly implementable, even if it weren’t for the precedent that we already have of Jonathan’s 2009 Coherence system which was already cited in the 2012 Bainomugisha review as being the only reactive system supporting both glitch freedom and bidirectional relations. Cooper & Krishnamurthi’s 2006 FrTime paper is likely another example, since the review is probably in error as just this capability is advertised in section 3.5 on Cycles.
I don’t find either of those systems’ support for bidirectional relations fully satisfactory. I’d prefer a Fabrik-type system which computes just the portion of dataflow relevant for a particular update and which pushes the description of computations out of the system.
Patrick isn’t too interested in bidirectional arcs since compilers and their tool chains tend to work on tree-structured data. However what he is interested in is managing lifetimes of objects in the computation for good memory management. From-scratch consistency properties could be helpful here since any “purely derived” computed could be cleared out of memory when things got tight. Tom Larkworthy had observed he considered Haskell’s reactivity a failure due to lack of memory management.
Ergonomic problems with preact-signals
I mentioned to Patrick I’d found serious ergonomic problems with preact. One of them is peculiar to it – despite being openly welcoming of framework building on top of preact’s internals this has to be done with respect to its name mangling which renames all non-API members to single character names through this registry. This reflects the really perverse incentives which JS library builders and particularly preact seem to feel themselves under – competing to shave a couple of bytes off the bundle size is seen as a much bigger win than community ergonomics. Unfortunately this likely reflects a real influence on developers’ decision-making as they shop around for frameworks. This decision has received a good amount of pushback from preact’s community but is too long entrenched to overturn.
We don’t want to encourage folks to use Preact without our property mangling, since that effectively creates a fork of Preact with a different API, and plugins don’t account for that being the case
I noted Stephen Kell’s observation that JS framework authors’ obsessive shaving of bytes was quite dissonant with the public’s experience of the web where almost every page was slow and bloated with rudundant junk and unoptimised ads. Patrick remarked that a page which included a single image would wipe out any gains from such byte golfing behaviour – it really reflects an aesthetic/polemic than something that benefits a community’s values.
The second ergonomic difficulty is its poor debuggability/observability. This is naturally exacerbated by the
name mangling choice but even once I adopted a hand-rolled
unmangled build
I still find it extremely hard to get good insight into why a computed/effect has actually notified in a non-trivial case.
Since the recursion has been unrolled into preact-signals’ batch() the information might not even readily be available.
There are plenty of complaints about this but the core team are
naturally more responsive to incentives for byte-shaving and nanosecond-sparing.
It’s absolutely essential in any user-facing reactive system that there should be absolutely clear access to the information “which signal’s update is responsible for this notification”. Tom Larkworthy has started to build tooling around this as part of Lopecode and at the 2025 Substrates workshop demonstrated a “flame graph” tracking a notebook’s reactive values and allowing visual diagnosis of why they are updating.
Glitches are just the tip
Given the extremely murky history of community understanding of glitches, one is sobered in the face of many other epiphenomena that a real reactive system needs to deal with, specially under the headings of
- Reactions, or notionally “pure” arcs which kick off further modifications of the graph’s content or structure
- Asynchronous activities in the dataflow where requests are made to external systems for updates
- Error handling
FrTime has unusually good handling of the first point, Observable of the second, and Coherence of the third. We need a system with stable and excellent behaviour in all three headings.
Note that these directions are somewhat orthogonal to glitches – the difficulty and value of being glitch-free increases with our increasing competence in these directions.
Unavailable values
I sketched to Patrick my proposed solution to the 2nd and 3rd points, unifying handling of errors and asynchrony under a common mechanism responding to “design incompletion for any reason”. I named a special reactive payload as an “unavailable value” indicating that the design was incomplete either as a result of depending on pending I/O or else of a design/syntax error in the system. This is described on its own page at unavailable value.
Helpful pointers
Patrick finished with a few helpful pointers to related frameworks. Firstly an RPC framework from Cloudflare/Kenton Varda named Cap’n Web that was a kind of dual to GraphQL in its ability to remotely express sequential actions captured locally, Mark Miller and Tom van Cutsem’s work on JS Proxies (2010) stemming from Mark’s earlier work on the Java distributed capabilities language E. And finally to Jon Kuperman, a TC39 committee member based in London.
On to Clemens
Later in the week after relaying a lot of this chat to Clemens we got to brass tacks seeing just how it is that commodity signals prevents bidirectional influence. We built a little Webstrate to test this out in, but it is clearly impossible by construction. You have to start with a signal and after that you are sunk since symmetry/glitch freedom are impossible. I floated an idea of “malleable signals” that could start out being agnostic as to whether they were signal/computed and could float up and down in purity as arcs were added/removed from them. The biggest draw of the signal/computed split is being easily able to inspect which parts of a design need to be marshalled when it is transported from place to place and which can be recomputed through from-scratch consistency. We need to retain a dynamic version of this after axing the static distinction from the type system. Note that Infusion designs are already “opportunistically writeable” since the user is permitted to layer arbitrary “yellow” data layers wherever they like – this represents a similar dynamic “user-driven change of provenance/transportability”.
Hierarchy of good functions
Finally the idea of the “hierarchy of goodness” that could be enjoyed by functions along the arcs:
- The identity – which in imperative memory ontologies appears as “aliasing”. “The same content knowably in more than one place”, which could be honoured by genuine aliasing in the underlying memory model, but at the very least should be trivially write-through, that is, “The same content knowably writeable at more than one address”.
- Linear functions – genuine linear functions such as
C = 5 * (F - 32) / 9, boolean NOT, etc. which can be “invertible on sight” when seen by the parser without the user needing to do anything about it. - Manually inverted functions – the user manually supplies an inverse and is assumed to know what they are doing.
- Good functions proper – A closed algebra of blessed functions not doing excessive computation and likely not invertible at all
- Anything else